웹 사이트(
web site),
하이퍼링크(
hyperlink), 데이터(data),
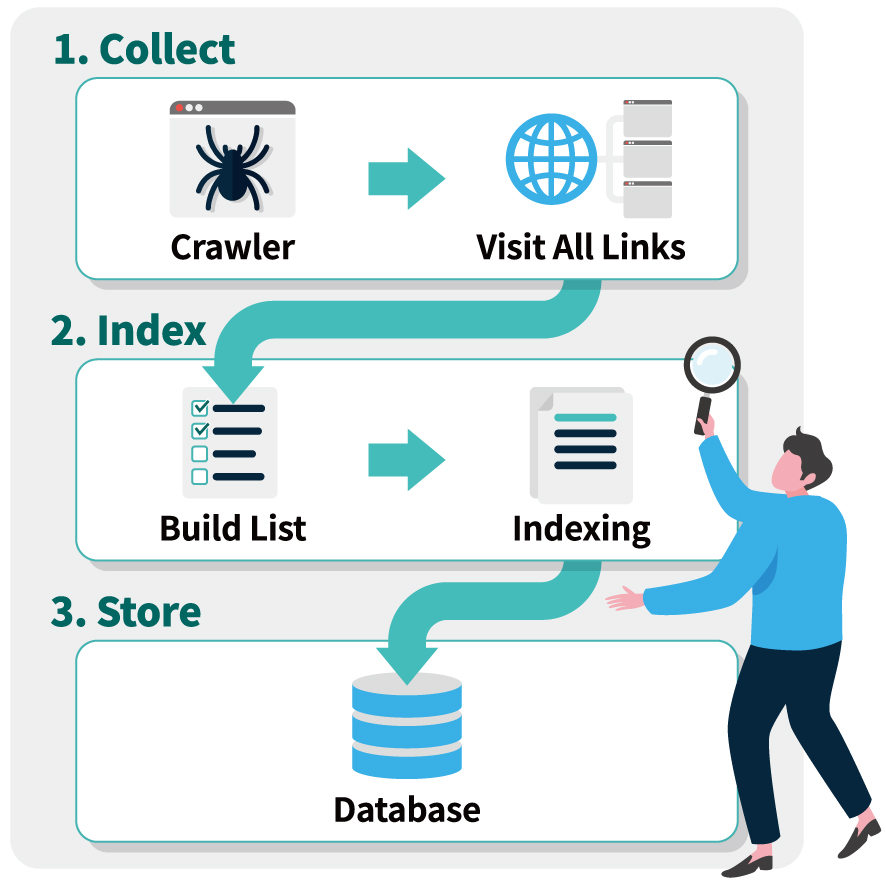
정보 자원을 자동화된 방법으로 수집, 분류, 저장하는 것.
크롤링을 위해 개발된 소프트웨어를 크롤러(crawler)라 한다. 크롤러는 주어진
인터넷 주소(
URL)에 접근하여 관련된
URL을 찾아내고, 찾아진
URL들 속에서 또 다른
하이퍼링크(
hyperlink)들을 찾아 분류하고 저장하는 작업을 반복함으로써 여러 웹 페이지를 돌아다니며 어떤 데이터가 어디에 있는지 색인(
index)을 만들어
데이터베이스(
DB)에 저장하는 역할을 한다.
크롤링과 유사한 개념으로 소프트웨어를 통해 대상
웹사이트와 같은
데이터 소스에서 데이터 자체를 추출하여 특정 형태로 저장하는 스크래핑(scraping) - 데이터 스크래핑(data scraping)이라고도 한다 - 이 있다.
빅데이터 분석에서는 크롤링을 통해 필요한 데이터가 어디 있는지 알아내고, 이를 스크래핑을 통해 수집, 저장 하여 분석에 사용하는 것처럼 두 기술을 결합하여 사용하기도 한다.
크롤링 기술이 악용되어 정보를 무단으로 복제하게 되면 지식재산권 침해 문제가 발생할 수 있다. 이러한 경우를 사전에 방지하기 위해 웹 페이지 소유자는 웹 페이지에 로봇 배제 표준(robots
exclusion standard)을 사용하여 접근 제한에 대한 설명을 robots.txt에 기술한다. 또는 ‘noindex’
메타 태그
(meta tag)를 사용하여 크롤러로 검색 색인이 생성되는 것을 차단할 수 있다.