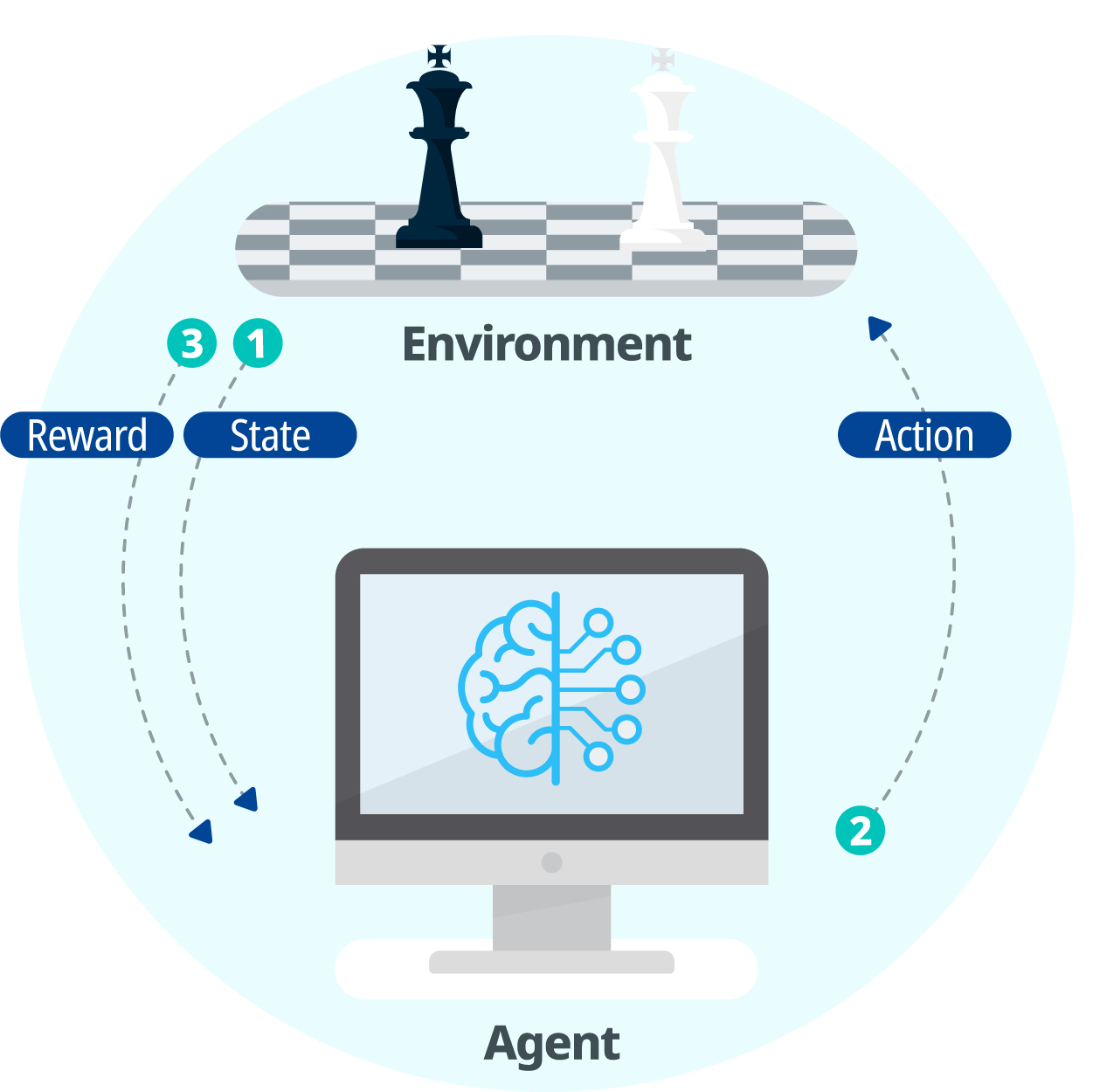
기계 학습 중 컴퓨터가 주어진 상태(state)에 대해 최적의 행동(action)을 선택하는 학습 방법. 강화형 기계 학습은 지도형/비지도형 기계 학습에 이용되는 훈련 데이터 대신, 주어진 상태에 맞춘 행동의 결과에 대한 보상(reward)을 준다. 컴퓨터는 보상을 이용하여 성능을 향상시킨다. 주로 게임이나 로봇 제어 등에 적용된다.
예를 들어, 체스를 두는 컴퓨터 프로그램을 학습시킬 때, 경우의 수가 너무 많고(약35의 100승) 정해진 하나의 답이 없으므로, 학습 훈련 데이터로 입력(주어진 상태)에 대한 출력(가장 적절한 행동)을 제공하기는 쉽지 않다. 하지만 체스 게임이 종료되면 그 직전에 둔 일련의 수(手, 행동)들이 좋았는지 나빴는지를 학습 알고리즘에게 알려 줄 수 있다. 이렇게 행동의 좋고 나쁜 정도를 학습 알고리즘에게 알려 주는 것을 보상(reward) 또는 강화(reinforcement)라고 하며, 이러한 정보를 이용하는 기계 학습이 강화형 기계 학습(이하, '강화 학습')이다. 강화 학습의 대상이 되는 컴퓨터 프로그램을 에이전트(agent)라고도 한다. 에이전트는 주어진 상태(state)에서 자신이 취할 행동(action)을 표현하는 정책(policy)을 수립한다. 에이전트가 최대의 보상을 받을 수 있는 정책을 수립하도록 학습시키는 것이 강화 학습의 목표이다. 강화 학습의 주요 응용 분야로는 게임과 로봇 제어를 들 수 있다. 1992년 IBM의 제럴드 테사우로(Gerald Tesauro)가 강화 학습을 이용하여 개발한 백개먼(Backgammon) 게임(TD-Game)은 인간 챔피언과 유사한 수준에 도달했고, 2016년 딥마인드(DeepMind)가 개발한 강화 학습 기반의 소프트웨어 알파고(AlphaGo)는 세계 정상급 바둑 기사들을 꺾었다. 로봇 제어 분야에서는 2000년대 후반 모형 헬리콥터의 곡예 비행에 강화 학습이 성공적으로 적용되었고, 자율 주행 자동차 개발에도 강화 학습이 이용된다.
※ 강화형 기계 학습에서는 지도형이나 비지도형 기계 학습의 ‘입력’, ‘출력’ 용어를 사용하지 않고 ‘상태(state)', '행동(action)' 단어를 사용한다. ※ 백개먼 게임: 주사위를 굴려 열다섯 개의 말을 전부 자기 쪽 진지로 먼저 모으는 쪽이 이기는 보드 전략게임 ※ TD-Game 관련 자료: 제럴드 테사우로(Gerald Tesauro), ‘Temporal Difference Learning and TD-Gammon’, Communications of the ACM, March 1995